
华为近日宣布,将于2026年世界移动通信大会(MWC 2026)期间正式启动A2A-T(Agent-to-Agent for Telecom)协议配套软件的开源计划。此前,A2A-T协议由全球电信产业伙伴于2026年2月6日在TM Forum Accelerate Week上联合发布,开源举措旨在通过开放协作加速智能体通信标准的规模化应用,推动电信场景下多智能体协同的落地。
在电信网络的运维后台,当故障排查智能体需要和资源调度智能体协同处理网络拥塞时,跨系统的通信壁垒往往会拖慢响应速度;在客户服务场景,多渠道的AI客服智能体也需要统一的逻辑协同,才能为用户提供一致的服务体验。这些真实存在的行业痛点,正在催生一套统一的智能体通信标准——而华为的开源计划,正是要把这套标准从纸面落到实处。
A2A-T(Agent-to-Agent for Telecom)协议并非华为单独推出的技术标准,而是由全球电信产业伙伴于2026年2月6日在TM Forum Accelerate Week上联合发布的成果。这套协议专门针对电信场景的智能体通信需求,定义了智能体间的交互规范、数据格式与协作流程,解决了不同厂商、不同场景下智能体“听不懂、联不通”的核心问题。
华为此次宣布在MWC 2026期间启动协议配套软件的开源计划,相当于为产业伙伴提供了一套可直接复用的技术底座。开发者无需从零开始适配通信标准,只需基于开源软件进行二次开发,就能快速打造符合A2A-T规范的智能体应用,大幅降低技术门槛与研发成本。
对于电信行业而言,智能体的价值从来都不是单一存在的,而是来自于多智能体的协同网络。比如一个覆盖全国的5G网络,需要数十甚至上百个不同功能的智能体协同工作,从基站状态监控到流量调度,再到用户需求响应,任何一个环节的协同不畅都会影响整体效率。
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录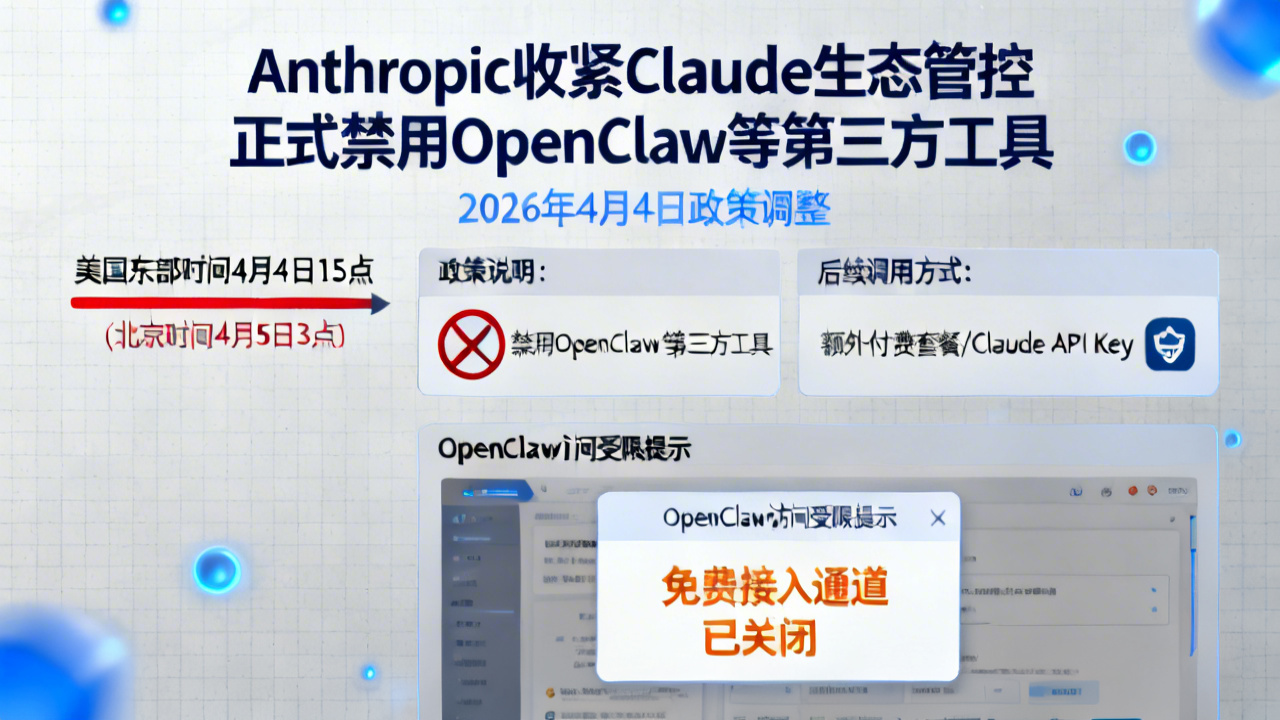
14 小时前
2026年4月4日,大模型厂商Anthropic正式官宣生态政策调整:从美国东部时间4月4日15点(北京时间4月5日3点)起,旗下Claude大模型将禁用OpenClaw等第三方工具,用户后续仅能通过额外付费套餐或Claude API Key调用相关工具。该政策将率先在OpenClaw落地,未来覆盖全部第三方工具链,是大模型厂商收紧生态控制权、加速商业化的标志性动作。

20 小时前
近期Meta、微软、谷歌等海外头部科技企业相继公布天然气电厂建设计划,为旗下高速扩张的AI数据中心提供稳定电力支撑。随着生成式AI普及,单座AI算力中心能耗是传统数据中心的3-5倍,现有公共电网已难以满足企业爆发式算力供电需求,化石能源供电方案也引发了业内对碳目标达成、长期运营风险的广泛讨论。

20 小时前
据科技媒体The Information及行业分析师Eric Newcomer披露,AI大模型厂商Anthropic已于近期完成对秘密运营的生物科技AI初创公司Coefficient Bio的收购,本次交易为全股票形式,总对价达4亿美元。这是Anthropic首次落地生命科学垂直领域布局,也标志着大模型厂商商业化正加速向生物医药赛道渗透。

20 小时前
2026年以来,微软、Meta、Google等全球科技巨头先后启动配套天然气发电厂建设项目,以满足AI大模型训练、推理所需的超算数据中心爆发式增长的能耗需求。行业测算显示,头部AI算力集群的单位能耗是传统数据中心的5-10倍,这一能源布局已引发行业关于碳排放、长期能源结构合理性的广泛讨论。

21 小时前
近期Anthropic源代码泄露事件中,安全研究者发现针对其旗下代码大模型Claude Code的新型prompt逃逸攻击路径,可绕过内容安全审查执行违规操作,而该类漏洞此前Anthropic公开表示已完成修复。目前该漏洞可导致代码生成环节出现恶意植入、数据泄露等风险,Anthropic尚未就新漏洞给出官方回应。

21 小时前
美国科技媒体Digital Trends近期发布的行业调查显示,全球已有超6成大中型保险公司引入AI系统负责核保风控、理赔核查等核心业务环节。美国消费者权益组织2024年调研数据显示,37%的拒赔案例由AI算法单独判定,其中42%存在事实认定偏差,相关算法决策的公正性问题已引发多国监管部门重点关注。
21 小时前
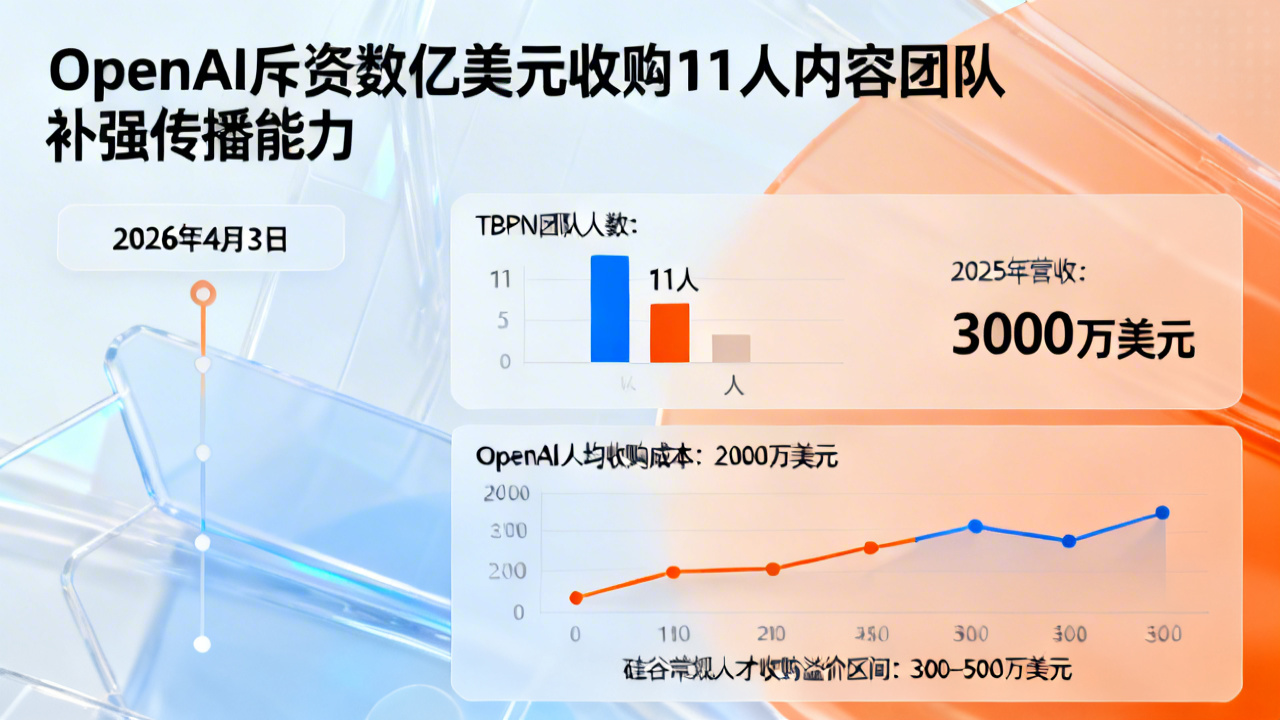
2026年4月3日,全球人工智能头部企业OpenAI宣布完成对美国科技访谈节目运营商TBPN的收购。据英国《金融时报》知情人士披露,本次收购对价达小几亿美元,标的团队仅11人,2025年全年营收达3000万美元。本次交易是OpenAI强化对外传播能力、重塑公众叙事体系的核心战略布局,也是2026年开年以来AI领域金额最高的内容生态类收购案。

21 小时前
2026年4月3日,阿里通义实验室正式发布视频创作大模型Wan2.7-Video,该模型支持文本、图像、视频、音频全模态输入,可实现从画面结构、局部细节到时序剧情的多维度编辑,用户仅需输入自然语言指令即可完成捏脸、换角色、改剧情等操作,同时自动保持光影材质一致性,大幅降低专业视频创作门槛。

如果追不上光,那就成为光!









 滇公网安备 53252802528133号
滇公网安备 53252802528133号
