工具介绍
Omni AI Video是基于自研Omni AI模型打造的多模态AI视频生成工具,核心定位为创作者提供一站式AI视频工作流解决方案。和市面上同类AI视频工具相比,它支持文本、图像、音频、视频多类输入模态,覆盖从创作、编辑到视觉参考生成的全流程需求,解决了传统AI视频工具生成速度慢、不支持真人参考素材的痛点,可适配不同尺寸、分辨率的视频产出需求,能够帮助创作者大幅降低视频制作的人力、时间成本,尤其适合需要高频产出视频内容的从业者使用。
效果展示/案例参考
用户上传真人参考图+文字描述,可生成和参考人物形象高度一致的剧情类短视频,画面自然无违和感;上传产品图像素材搭配宣传音频,可生成音画同步的电商产品宣传短视频,支持1080P高清分辨率输出;输入纯文字创意描述,可快速生成对应风格的创意短视频,支持横屏、竖屏、正方形等多尺寸适配,无需二次调整即可直接匹配不同平台的发布要求。
核心功能
- 多模态输入支持 - 支持文本、图像、音频、视频多类素材输入,可自由组合调用参考内容
- 多规格视频生成 - 支持5s时长,16:9、9:16、1:1等7类比例,480P到1080P多分辨率视频产出
- 真人参考素材支持 - 可导入真人参考图像生成对应人物的视频内容,解决同类工具人物还原度低的问题
- 快速生成服务 - 视频生成仅需5-8分钟,无需排队等待,远快于同类平台30+分钟的生成速度
- 多素材参考功能 - 最多支持上传12份参考素材,可融合多份素材的风格、内容生成目标视频
- 首尾帧自定义 - 支持自定义视频首尾帧,精准控制视频的开篇和结尾效果
- AI图像生成 - 除视频生成外,还支持AI图像创作,满足创作者多元内容产出需求
使用流程
- 步骤1:进入Omni AI Video官网,选择创建视频功能
- 步骤2:按需上传参考图像、视频、音频素材,最多可上传12份参考内容,也可直接输入文字描述
- 步骤3:选择需要生成的视频时长、比例、分辨率参数,可自定义首尾帧效果
- 步骤4:点击生成按钮,等待5-8分钟即可获取生成的视频内容,支持导出下载
使用场景
- 场景1:短视频创作者快速生成剧情类、种草类短视频,导入真人IP参考图即可生成对应IP的内容,无需真人出镜拍摄
- 场景2:新媒体运营人员制作各平台宣传物料,可选择对应平台的视频比例,快速生成适配抖音、B站、小红书等多平台的视频内容
- 场景3:创意从业者快速将文字灵感转化为可视化视频样片,降低前期试错成本,提升创意落地效率
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
免责声明:本网站仅提供网址导航服务,对链接内容不负任何责任或担保。
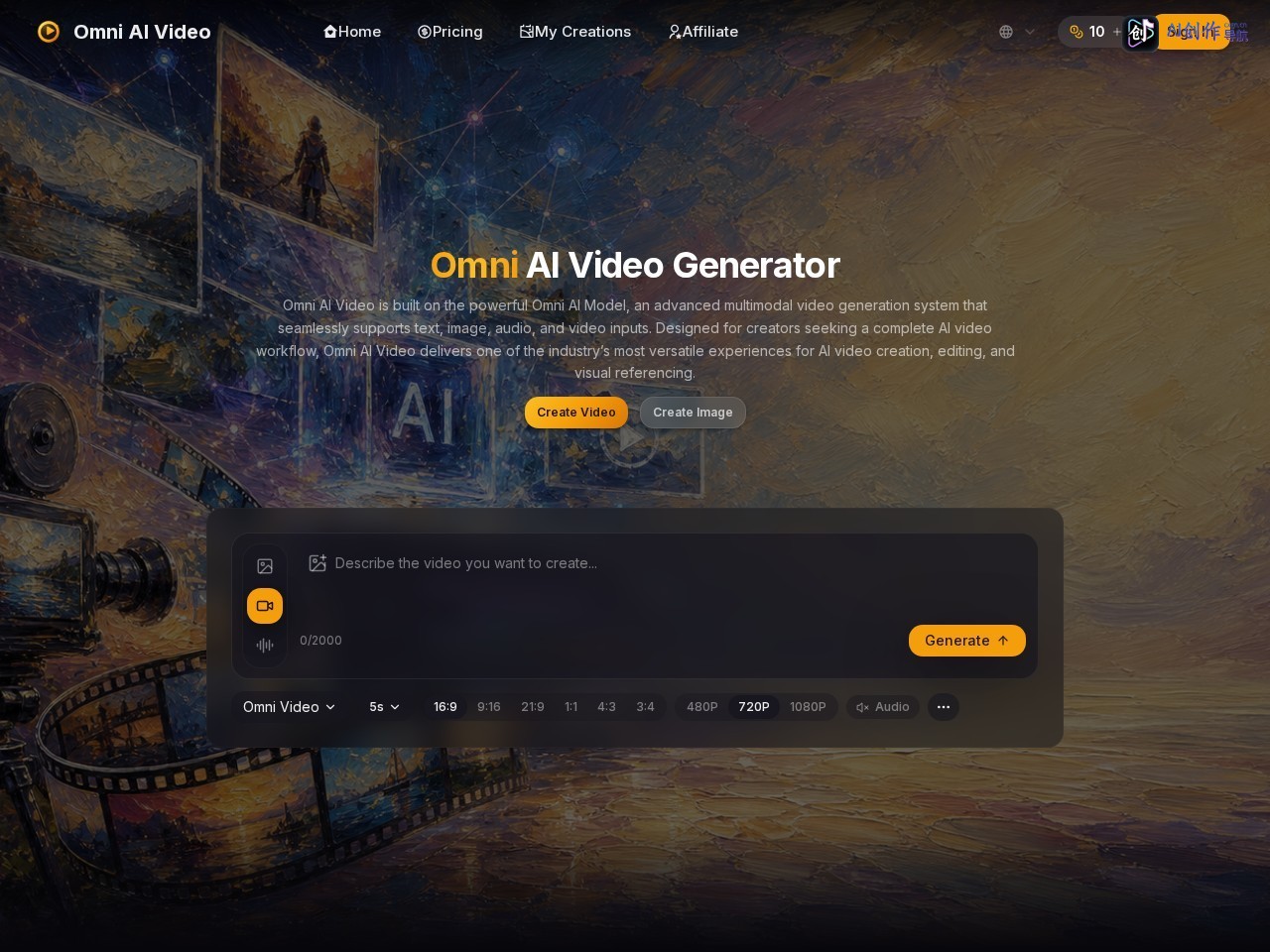 网站截图
网站截图






















 滇公网安备 53252802528133号
滇公网安备 53252802528133号