工具介绍:
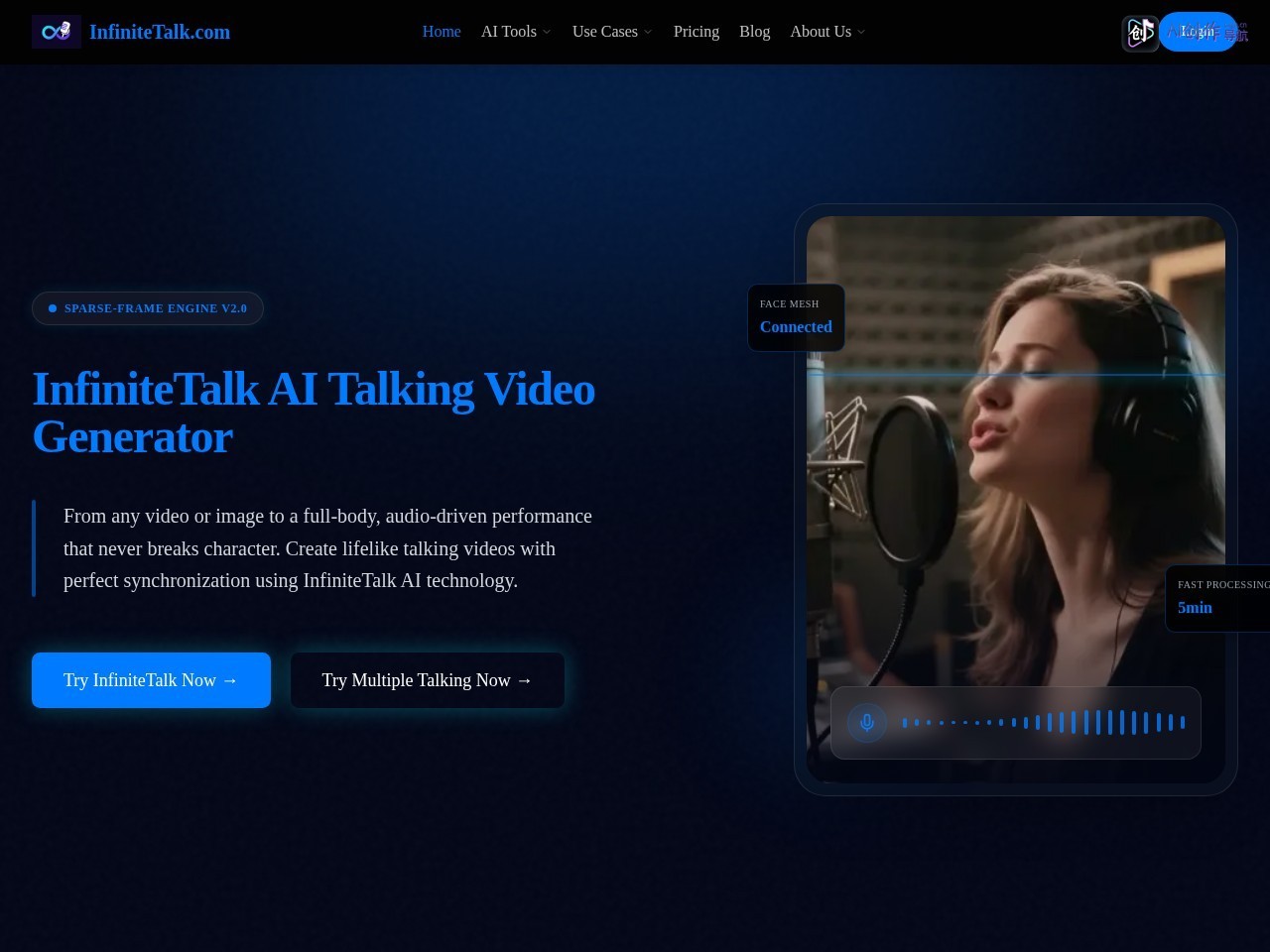
InfiniteTalk是搭载Sparse-Frame Engine V2.0技术的AI对口型口播视频生成工具,核心定位是帮助用户将任意图片、视频素材转化为音频驱动的真实动态表演内容。不同于普通对口型工具仅能匹配唇部动作,该工具可同步人物头部动作、肢体姿态、微表情等细节,生成效果自然连贯,同时打破行业时长限制,支持任意时长内容生成,适配从短视频到长音频转视频的全场景创作需求,大幅降低口播类视频的制作门槛。
效果展示/案例参考:
输入静态人物照片+2小时播客音频,可生成完整的长视频内容,全程唇形与音频完全匹配,人物头部自然摆动、挑眉、眨眼等微表情真实流畅,无跳脱、崩坏的异常表现;输入1分钟中文口播短视频+英文配音,可快速生成英文版本视频,口型与英文发音完全同步,整体观感和原生拍摄的英文口播内容无差异。
核心功能:
- 稀疏帧视频配音:先进算法同步唇形、头部动作、肢体姿态、微表情,输出内容真实自然,无割裂感
- 无限时长视频生成:打破时长限制,支持任意时长视频生成,适配长内容创作需求
- 快速处理:常规时长内容5分钟即可完成生成,效率远超同类工具
- 人脸网格连通技术:保障面部动作连贯流畅,避免面部扭曲、错位等异常问题
- 多源素材导入:支持任意图片、视频作为输入基底,适配不同创作场景
- 全身动作驱动:除头部外还可同步全身姿态,生成完整的人物表演内容
使用流程:
- 步骤1:上传准备好的人物图片或视频素材作为创作基底
- 步骤2:上传需要匹配的音频文件,或输入文本生成对应配音
- 步骤3:等待系统自动处理完成后,导出同步好的口播视频即可
使用场景:
- 长内容视频化:将播客、有声书、课程音频转化为口播视频,无需真人拍摄即可丰富内容形态
- 跨境内容本地化:给原有视频替换不同语言配音,自动匹配对应口型,快速产出多语种内容
- 数字人内容制作:用静态数字人形象生成连续的口播内容,降低数字人视频的制作成本
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
免责声明:本网站仅提供网址导航服务,对链接内容不负任何责任或担保。
 网站截图
网站截图




















 滇公网安备 53252802528133号
滇公网安备 53252802528133号