工具介绍:
Apatero Studio是一款主打全链路AI多媒体内容生成的创作工具,核心定位是降低专业AI艺术创作的操作门槛,覆盖图像、视频、音频三类主流多媒体内容的AI生成需求。相比多数仅支持单类内容生成的同类工具,它无需用户在多个平台间跳转切换,即可完成音视图三类内容的制作,无需掌握复杂的AI参数调试技巧,普通用户也能快速产出符合商用标准的专业级AI艺术作品,适配各类内容生产场景。
效果展示/案例参考:
工具产出的作品覆盖多元风格,质量达到商用级标准:写实类AI图像光影自然、细节饱满,可对标商业摄影出片效果;二次元、国风等创意类AI图像风格统一,人物建模无明显崩坏、元素逻辑自洽;AI生成短视频画面流畅无闪烁,转场衔接丝滑,无明显AI生成瑕疵;AI音频可匹配内容调性生成对应风格的背景音乐、旁白配音,音色自然无机械感,可直接用于新媒体内容发布。
核心功能:
- AI图像生成:输入文字描述即可生成对应风格的AI图像,支持写实、二次元、国风等数十种主流风格选择
- AI视频生成:可基于文字prompt或已有参考图像生成短视频,支持时长、帧率等参数自定义调整
- AI音频生成:可匹配内容需求生成对应风格的背景音乐、配音旁白,支持音色、语速、音量自定义设置
- 风格预设模板:内置上百套商用风格预设,无需手动调整参数,一键生成符合行业标准的作品
- 作品批量导出:支持单次生成多组同需求作品,可批量导出不同分辨率、不同格式的成品文件
- 商用版权授权:合规输入生成的原创作品可获得商用授权,降低内容创作的版权风险
使用流程:
- 步骤1:进入Apatero Studio官网,选择需要生成的内容类型(图像/视频/音频)
- 步骤2:输入对应内容的文字描述,选择适配的风格模板或自定义生成参数
- 步骤3:点击生成按钮等待AI运算完成,在线预览生成的成品效果
- 步骤4:效果满意即可导出对应格式的文件,不满意可调整prompt或参数重新生成
使用场景:
- 新媒体运营场景:运营人员可快速生成公众号配图、短视频素材、账号背景音乐,大幅缩短内容生产周期,降低素材采购成本
- 设计创作场景:设计师可利用工具生成创意初稿、灵感参考图,辅助完成商业海报、宣传物料等设计项目
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
免责声明:本网站仅提供网址导航服务,对链接内容不负任何责任或担保。
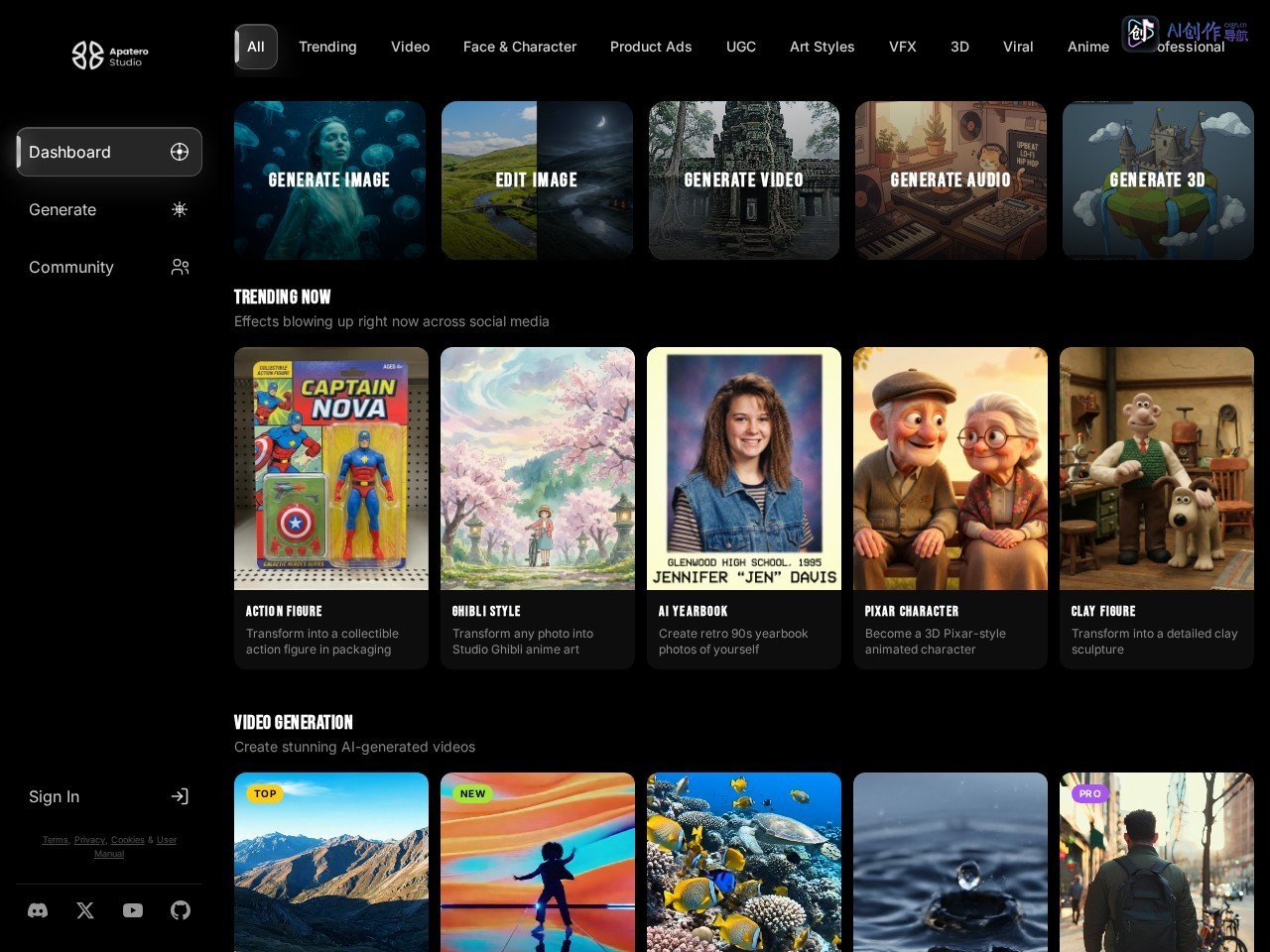 网站截图
网站截图



















 滇公网安备 53252802528133号
滇公网安备 53252802528133号