 网站截图
网站截图


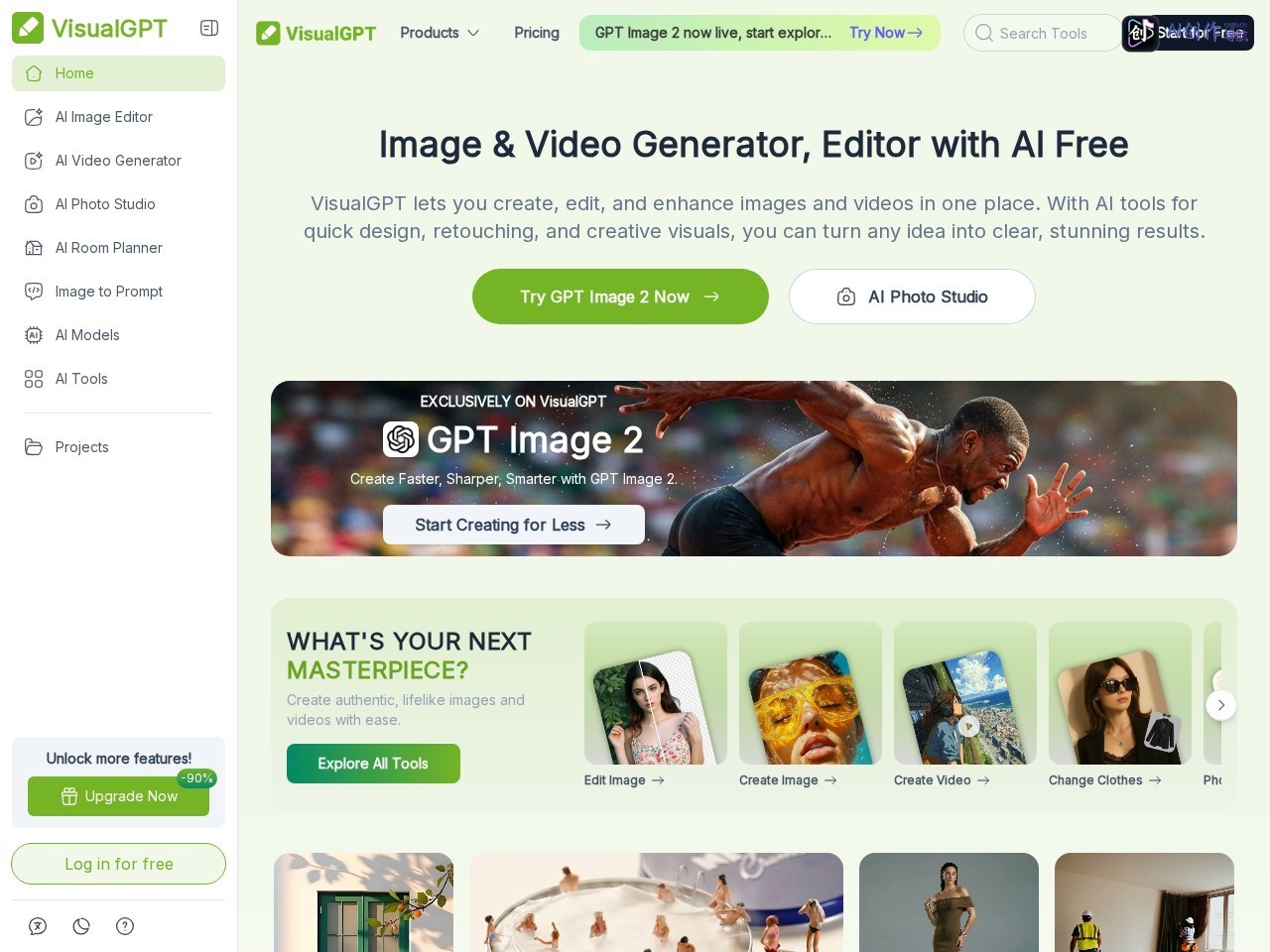
VisualGPT是一款融合GPT大模型与计算机视觉技术的多模态视觉创作工具,核心解决“视觉创作与文本交互割裂、提示词理解精准度低、多场景视觉需求适配不足”的痛点。工具以GPT强大的自然语言理解能力为核心,支持文本生成图像、图像交互问答、自然语言图像编辑等功能,可精准捕捉用户创意意图,生成高质量视觉内容,适配短视频素材制作、设计物料创作、视觉信息分析等多场景,成为全球创作者高效实现“文本-视觉”转化的核心工具。
短视频创作中,输入文案生成专属封面、场景插图、产品展示图,通过视觉问答功能快速分析参考素材的构图与色彩,优化创作方向;设计场景下,生成海报背景、创意插画,借助自然语言编辑实时调整细节,无需专业设计技能;营销人员可通过文生图功能快速制作产品宣传物料、活动海报,视觉问答助力分析竞品视觉设计亮点;自媒体人可生成个性化配图、短视频片段,通过创意扩展功能突破灵感瓶颈;科研/教育场景中,上传图表、示意图,通过视觉问答快速提取关键信息,辅助内容创作。
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录















 滇公网安备 53252802528133号
滇公网安备 53252802528133号