 网站截图
网站截图


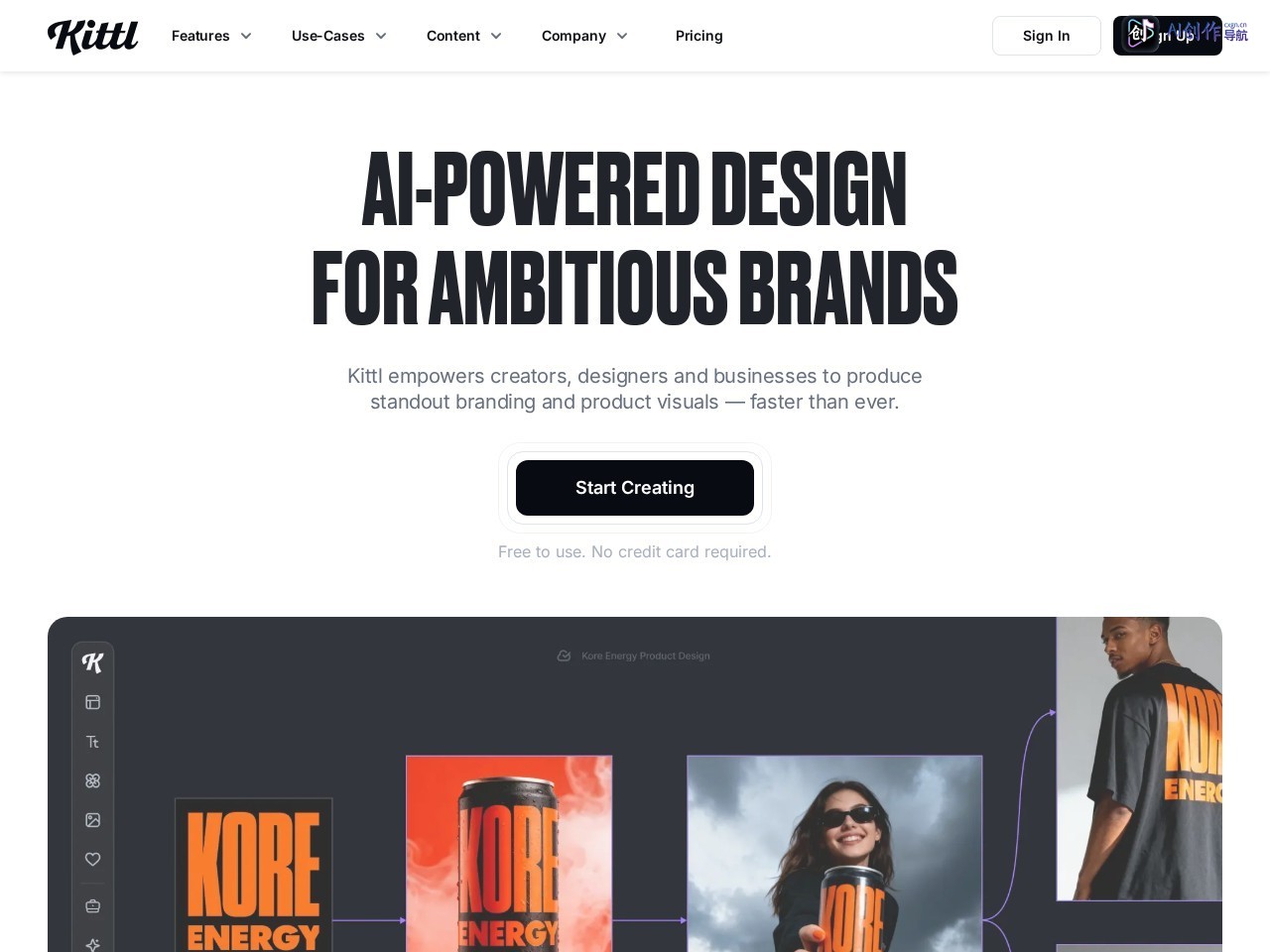
Kittl是一款基于人工智能的在线设计平台,旨在让创意人员无需考虑技术问题即可生成商业设计。该平台利用先进的算法和机器学习,用户通过简单的文本提示就能创建高质量的设计元素,如插图、字体、照片、图标和纹理等。它提供了成千上万的专业设计模板,可用于个人或商业项目,并拥有海量免费素材库,包括上百万免费素材,用户可随意拖放图标、插画等。Kittl在2025年1月完成了3600万美元的B轮融资,目前月访问量接近300万,展现了其快速增长和市场认可度。
AI生成设计元素:通过文字提示生成矢量标志、图标、图像和剪贴画。
实时文本变形与编辑:提供数千款可定制字体,用户可轻松调整文本样式。
魔法着色与调色板:从流行调色板中选择颜色,一键替换设计中的颜色。
海量模板与素材库:提供上万专业模板和数百万免费照片、插图、图标等资源。
产品实景展示:直观预览设计在T恤、海报等实物上的效果,所见即所得。
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录















 滇公网安备 53252802528133号
滇公网安备 53252802528133号