 网站截图
网站截图


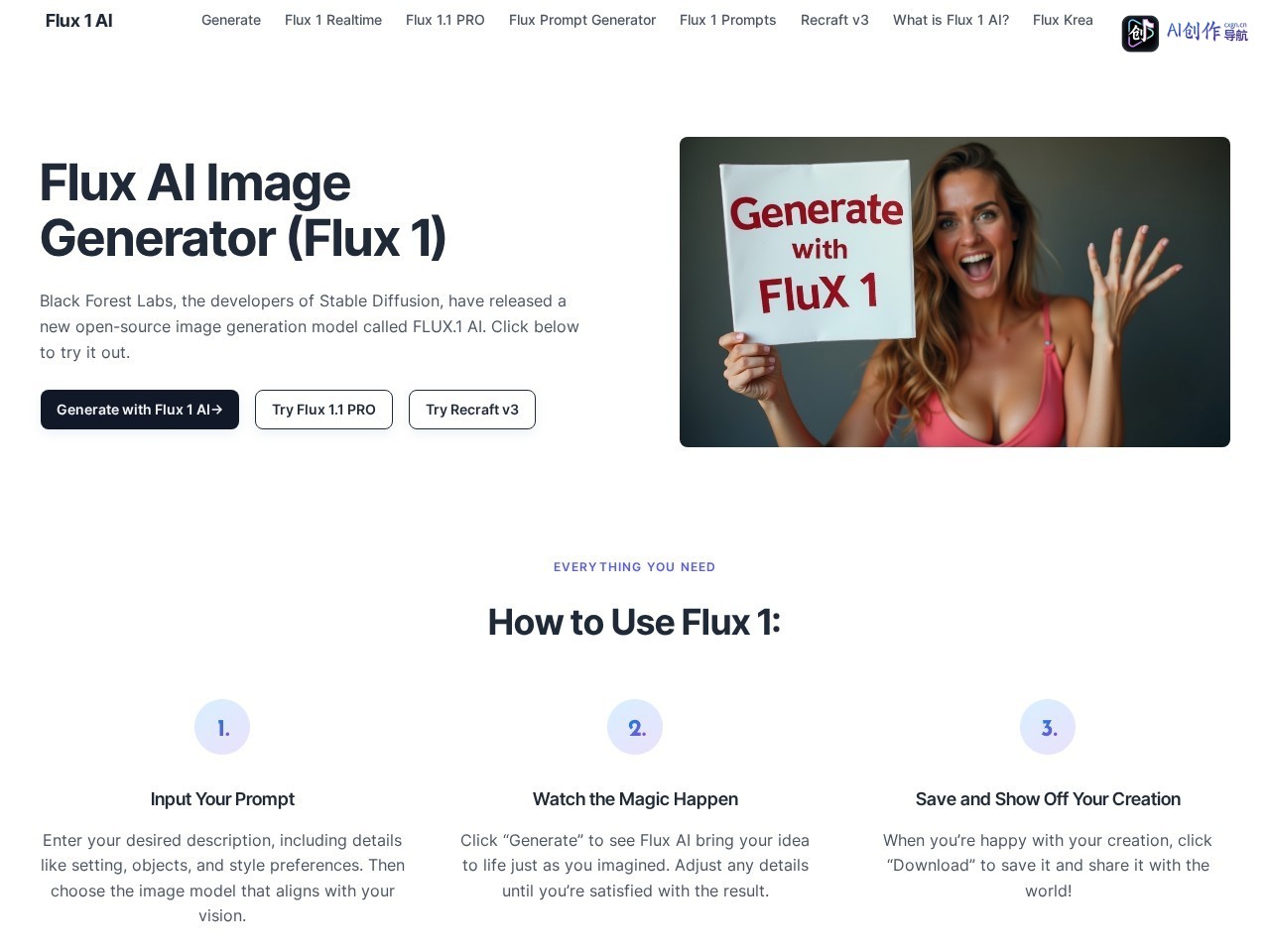
Flux 1 AI是由Stable Diffusion原开发团队Black Forest Labs推出的开源AI图像生成模型,官网提供免费在线生成服务,无需本地部署即可体验最新的FLUX.1系列AI绘画能力,还支持Flux 1.1 PRO、Recraft v3等多个热门AI图像模型切换使用。相比传统AI绘画工具,Flux 1 AI对文本提示的语义理解能力更强,生成图像的细节还原度更高、构图更自然,有效减少了AI常见的畸变问题,降低了普通用户体验前沿AI图像生成技术的门槛,适合各类创意创作需求。
不同场景下Flux 1 AI的生成表现都较为稳定:创意氛围图场景,输入“雨后雾蒙蒙的江南古镇巷弄,油纸伞,青石板路,暖黄灯光”,生成的作品层次清晰,氛围感拉满,光影过渡自然,没有明显的结构错误;创意logo场景,输入“极简风户外露营品牌logo,几何山形,低饱和色调”,输出的方案线条简洁,符合品牌定位,可直接用于初稿修改;插画创作场景,输入“治愈系中秋节兔子月饼插画,国潮风格”,生成的作品风格统一,元素结构准确,色彩搭配协调,满足商用初稿需求。
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录

















 滇公网安备 53252802528133号
滇公网安备 53252802528133号