工具介绍:
AnyToSpeech是一款纯在线的AI文字转语音工具,核心定位是为用户提供一站式多格式文本转音频服务,无需下载本地客户端,打开官网即可使用。不同于功能单一的同类转语音工具,它支持多种输入格式的直接转换,不仅能处理普通文本,还能直接解析PDF、图片、网页链接中的文字,自带多风格自然AI音色,生成音频接近真人发声,可直接导出MP3,适配个人创作者、中小企业的轻量化音频制作需求。
效果展示/案例参考:
不同场景下的输出表现清晰实用:口播文案转配音场景,输入短视频带货文案后,可选择自信坚定的女声、平和中性的男声等不同风格,生成的语音停顿自然,无明显机械感,可直接用于短视频发布;长文本PDF转有声书场景,上传整本电子书PDF后,可批量转换生成连贯音频,流畅度符合听读需求,直接做成可收听的有声书;图片转语音场景,实体书拍照、文章截图上传后,可自动提取文字转换为音频,快速把纸质内容转为可听内容。
核心功能:
- 文本转语音:支持输入任意普通文本,一键转换为自然AI音频,支持实时预览效果
- URL转语音:直接输入网页链接,自动提取页面文字转换为音频,省去复制粘贴步骤
- PDF转语音:上传PDF文档,批量提取文字转换为音频,适配有声书制作需求
- 图片转语音:上传图片自动提取文字,转换为音频,支持截图、实体书图片场景
- AI图像翻译:对图片内容翻译后转语音,满足跨境内容创作需求
- 音频转录:支持将音频反向转录为文字,覆盖多场景音频处理需求
- 多音色选择:提供多种不同风格、声线的自然AI音色,适配不同内容场景
- MP3格式导出:生成的音频可直接导出为标准MP3,方便存储和二次编辑
使用流程:
- 步骤1:打开AnyToSpeech官网,根据需求选择对应转换类型
- 步骤2:输入文本内容或上传对应文件,选择匹配的AI音色
- 步骤3:点击生成按钮,在线预览转换后的音频效果
- 步骤4:确认效果后导出MP3音频文件即可完成
使用场景:
- 场景1:有声书制作:创作者可快速将电子书、文稿转换为有声书,降低专业配音成本
- 场景2:内容配音:短视频博主、播客创作者快速生成口播、旁白,无需专业录音设备
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
免责声明:本网站仅提供网址导航服务,对链接内容不负任何责任或担保。
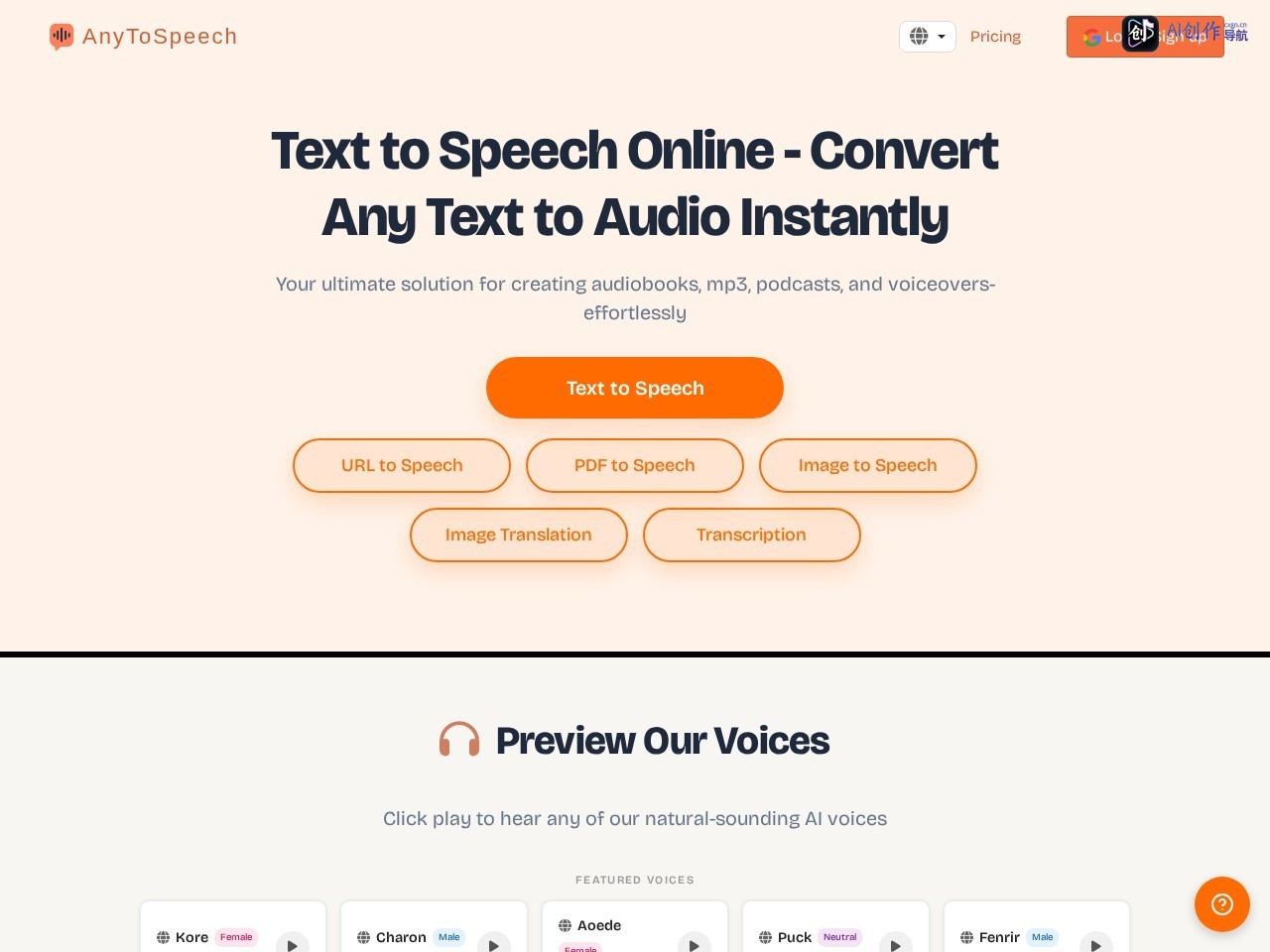 网站截图
网站截图




















 滇公网安备 53252802528133号
滇公网安备 53252802528133号