工具介绍:
DataLearner是专注大模型评测、数据资源与实践教学的知识平台,核心定位是为科研人员、企业、AI开发者提供可靠的大模型情报与选型参考。它打破了单一评测维度的局限性,同时上线客观跑分类的Artificial Analysis智能指数榜单,和基于全球用户匿名盲测的LMArena榜单,覆盖MMLU Pro、HLE、SWE-Bench等主流评测基准,数据定期更新,还支持不同大模型的自定义对比,相比同类榜单更兼顾客观性能与实际使用体感,能帮助用户快速筛选适配不同场景的大模型产品。
效果展示/案例参考:
如果用户要选型一款编程能力强的大模型,可直接进入编程单项评测榜单,查看各模型在对应基准上的跑分排序,快速筛选出Top3模型后,使用模型对比功能查看不同维度的能力差异,最终选出适配自身开发需求的产品;如果是企业需要选型通用大模型,可同时参考AA智能指数的综合跑分和LMArena的用户偏好评分,平衡性能与实际使用体验,避免单一维度选型的偏差。
核心功能:
- 综合榜单查询:同步展示AA智能指数、LMArena两大权威综合榜单,兼顾客观性能跑分与用户实际使用体感,全面衡量大模型综合能力
- 单项评测排名:覆盖数学、编程、Agent等多个细分维度的评测榜单,支持按场景筛选适配模型
- 多基准覆盖:支持MMLU Pro、HLE、SWE-Bench等主流评测基准的结果查询,满足不同维度的评测参考需求
- 模型对比功能:支持自定义选择多个大模型进行多维度能力对比,直观呈现各模型的优劣势
- 数据实时更新:所有榜单数据定期同步最新评测结果,确保用户获取到的是当下最准确的大模型性能信息
- 评测基准导航:汇总所有主流大模型评测基准的介绍与对应榜单入口,方便科研人员快速查找对应评测数据
使用流程:
- 步骤1:进入DataLearner大模型评测排行榜主页,选择需要参考的榜单类型(综合榜单/单项评测榜单)
- 步骤2:如果有明确的场景需求,可切换对应评测基准,查看该维度下的大模型排名情况
- 步骤3:挑选出意向大模型后,使用模型对比功能,对多个候选模型的多维度能力进行横向对比
- 步骤4:结合榜单数据与自身需求,确定最终适配的大模型产品
使用场景:
- 场景1:AI开发人员选型大模型,可通过编程、推理等单项榜单筛选出对应能力突出的大模型,提升开发效率
- 场景2:企业采购大模型前,可参考综合榜单的双维度数据,平衡性能与使用体验,降低选型成本
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
免责声明:本网站仅提供网址导航服务,对链接内容不负任何责任或担保。
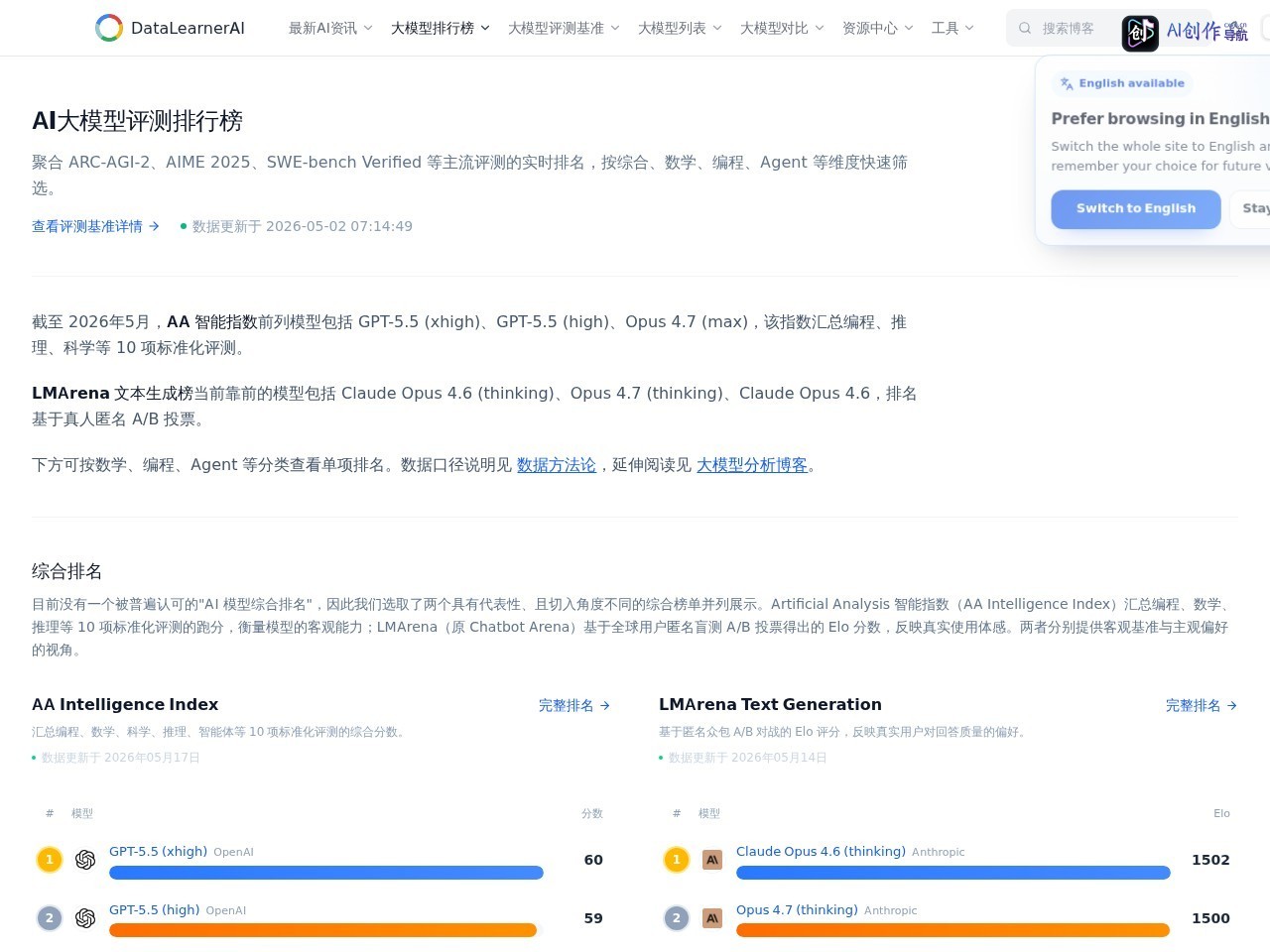 网站截图
网站截图


















 滇公网安备 53252802528133号
滇公网安备 53252802528133号