


最近我在整理 GPT Image 2 的图片 Prompt。
先看 3 张图:
| 产品图 Prompt | Prompt 结构 | 图到视频工作流 |
|---|---|---|
 |
 |
 |
很多人写 AI 图片 Prompt 时,会这样写:
生成一张高级感产品图,真实摄影,8K,商业海报。这类 Prompt 可以出图,但很难稳定复用。
因为模型不知道你真正要的是:
我更倾向于把 GPT Image 2 Prompt 当成一份“视觉设计 Brief”,而不是一串形容词。
多数可复用的图片 Prompt,都可以拆成:
用途:这张图用在哪里
主体:画面主角是什么
版式:主体、文字、留白、模块怎么摆
风格:摄影、3D、插画、UI、信息图等
细节:材质、光线、背景、镜头、比例
文字:需要出现哪些精确文字,放在哪里
约束:不要乱码、不要变形、不要水印、不要多余 Logo如果只写“高级感”,模型会自由发挥。
如果写清用途和版式,结果更像能交付的设计图。
这张图适合拆产品摄影 Prompt。
它不是单纯靠“高级感”,而是把产品图拆成了几个明确条件:
可复用 Prompt:
生成一张【产品类型】商业摄影图。
产品以【角度】展示,位于【干净背景 / 工作台 / 户外场景】。
保持产品的形状、比例、颜色、材质和关键结构准确。
使用【柔光 / 侧光 / 高反差光 / 自然光】突出【卖点】。
画面用途是【电商主图 / 品牌广告 / 详情页头图】。
不要添加虚假 Logo、乱码文字、额外按钮、变形结构或无关道具。适合改成:
这张图对应的是一个更通用的 Prompt 结构:
Prompt:一句话任务
Subject:主体
Composition:构图
Constraints:限制条件很多失败的 AI 图片,不是模型不会画,而是 Prompt 没有把这四层写清楚。
一个更稳的写法:
任务:生成一张【用途】图片。
主体:画面主体是【主体】,必须保持【关键外观】。
构图:主体位于【位置】,画面保留【文字区 / 留白区 / 模块区】。
风格:整体为【摄影 / 插画 / 3D / UI / 海报】。
限制:不要乱码、不要水印、不要多余 Logo、不要结构变形。这个结构特别适合做:
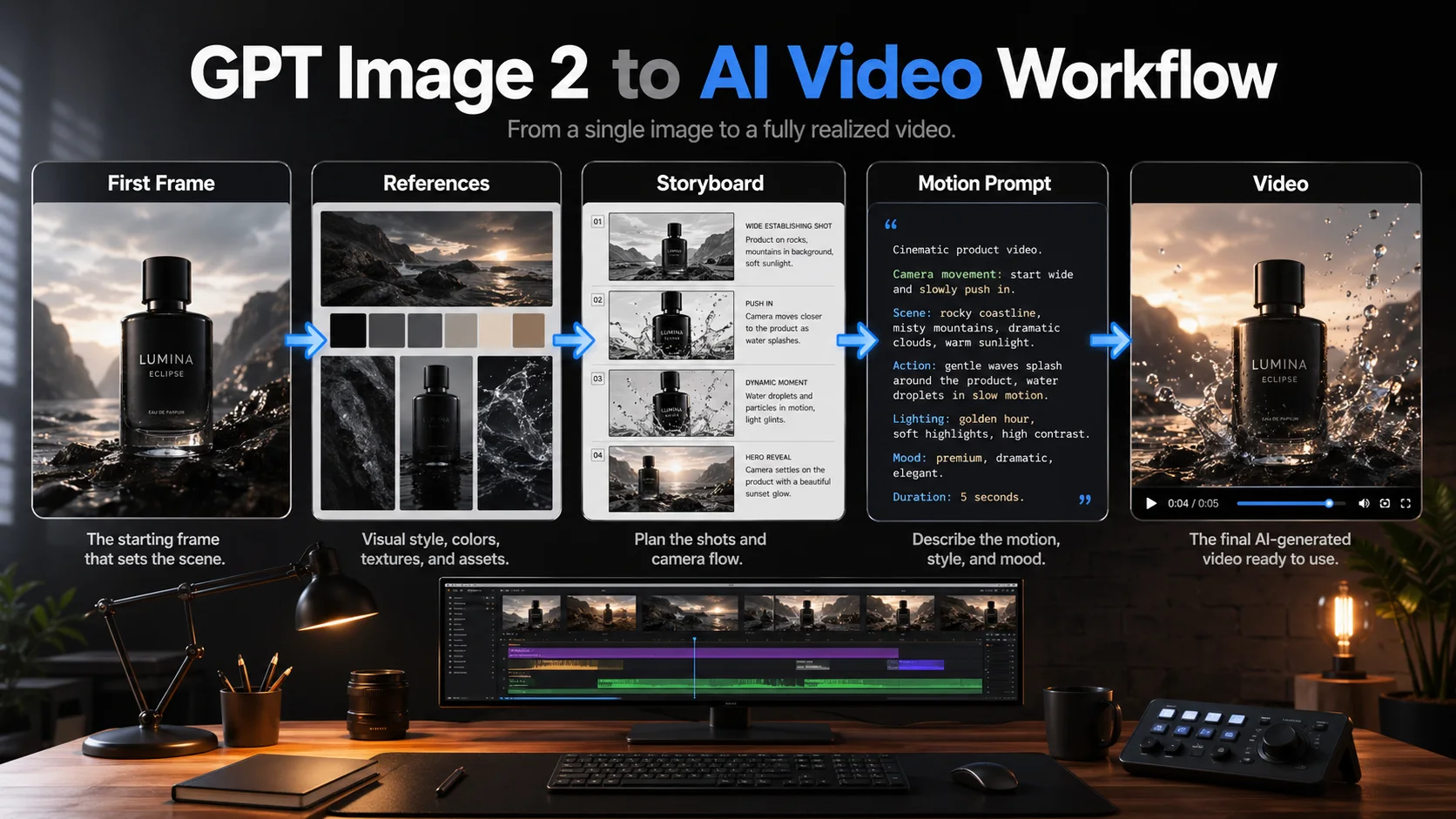
这张图不是单张图片生成,而是一个工作流:
首帧图
-> 参考图
-> 分镜
-> Motion Prompt
-> 视频结果如果你后续要从图片进入视频生成,这个结构很有用。
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
















 滇公网安备 53252802528133号
滇公网安备 53252802528133号