



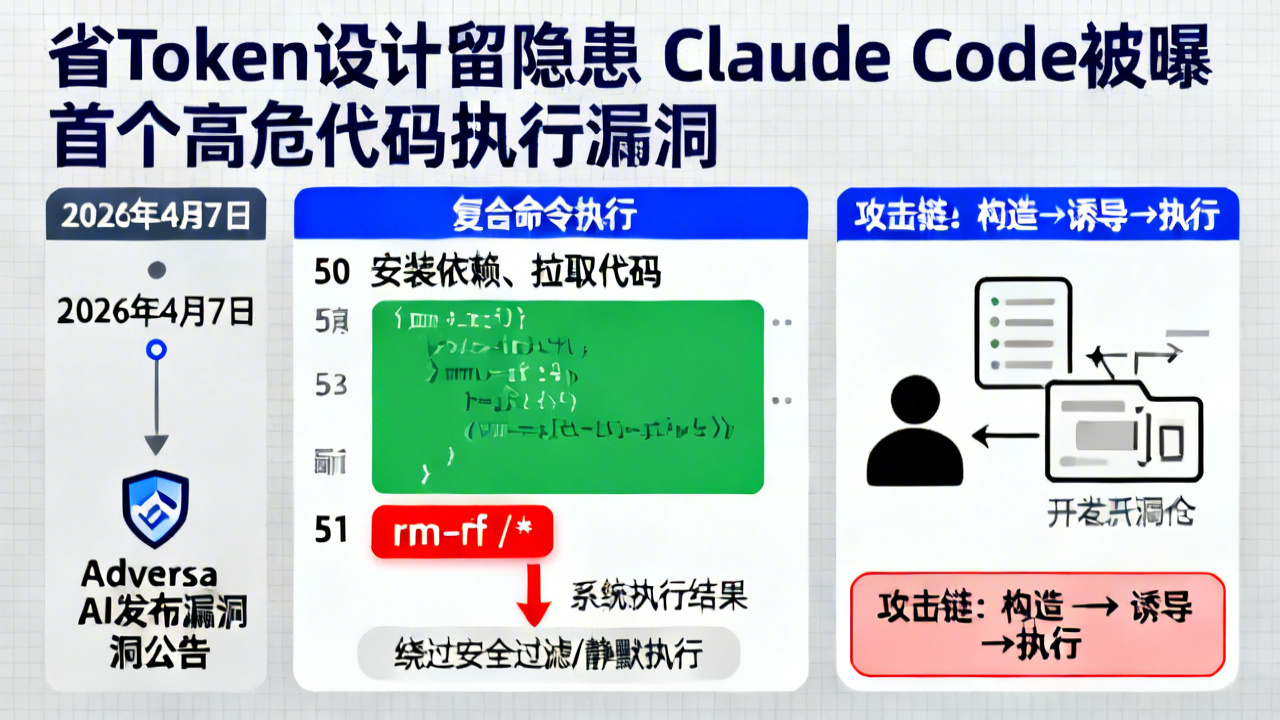
2026年4月7日,安全研究机构Adversa AI发布公告称,在Anthropic旗下AI编程助手Claude Code此前意外泄露的源代码中,发现首个高危代码执行漏洞:当工具处理超过50条子命令的复合命令时,会自动绕过所有内置安全过滤规则,第51条及之后的恶意代码可静默执行,攻击者可通过构造恶意开源仓库诱导开发者操作完成攻击。
 图源: 图像由AI生成
图源: 图像由AI生成Adversa AI在漏洞报告中披露了完整的复现流程:研究人员构造了一串由51条子命令拼接而成的复合指令,前50条均为安装依赖、拉取代码等正常操作,第51条则写入了清除本地磁盘的高危指令`rm -rf /*`,将这串指令输入Claude Code后,系统完全没有触发安全告警,直接执行了全部命令。
作为Anthropic旗下增长最快的AI编程工具,Claude Code原本内置了完善的命令安全校验机制,默认禁止执行curl、rm等可能造成数据泄露或系统损坏的高危指令。而此次漏洞的根源,是研发团队**为降低推理阶段的Token消耗,给命令审查环节设置了最高50条的截断规则**,超过阈值的子命令会直接跳过校验进入执行环节,相当于主动给恶意代码开了“绿灯”。
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录















 滇公网安备 53252802528133号
滇公网安备 53252802528133号