



当前生成式AI落地进入深水区,大量企业面临大语言模型(LLM)选型难题,本次梳理的27项核心评估维度,覆盖部署成本、推理性能、场景适配能力、合规性等多个层面,适用于OpenAI、Anthropic、国内厂商等推出的各类LLM产品,可帮助企业快速筛选匹配需求的模型,降低试错成本。
 图源: 图像由AI生成
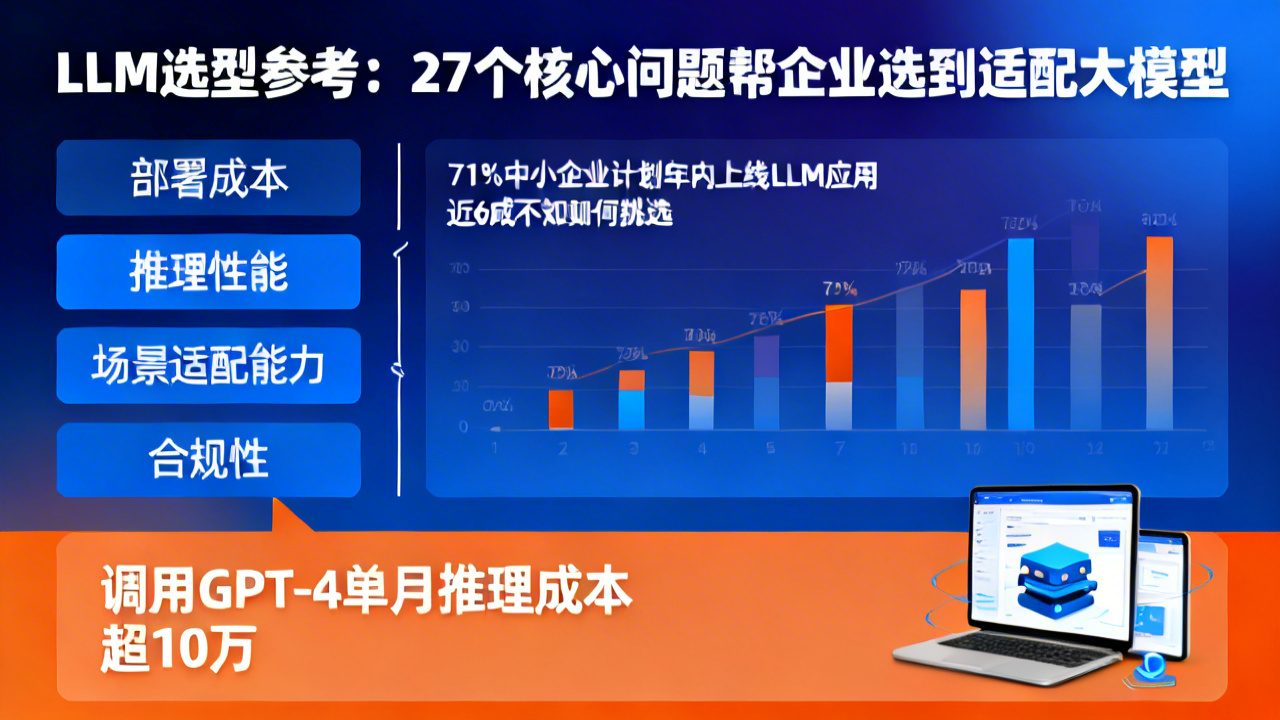
图源: 图像由AI生成据今年一季度生成式AI落地调研数据显示,国内有71%的中小企业计划在年内上线LLM相关应用,但其中近6成受访者表示,面对市场上数百款参数、定价、能力差异极大的LLM产品,不知道该如何挑选。
此前不少企业踩过盲目选型的坑:有的为了追求效果直接调用GPT-4,单月推理成本突破10万元,但实际业务场景仅需处理简单的客服问答,大量成本被浪费;有的为了省钱选择小参数开源模型,却没有做垂直领域微调,回答准确率不足60%,反而拉低了业务效率。行业普遍缺少一套可直接复用的通用选型框架,来降低企业的决策成本。
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录















 滇公网安备 53252802528133号
滇公网安备 53252802528133号