
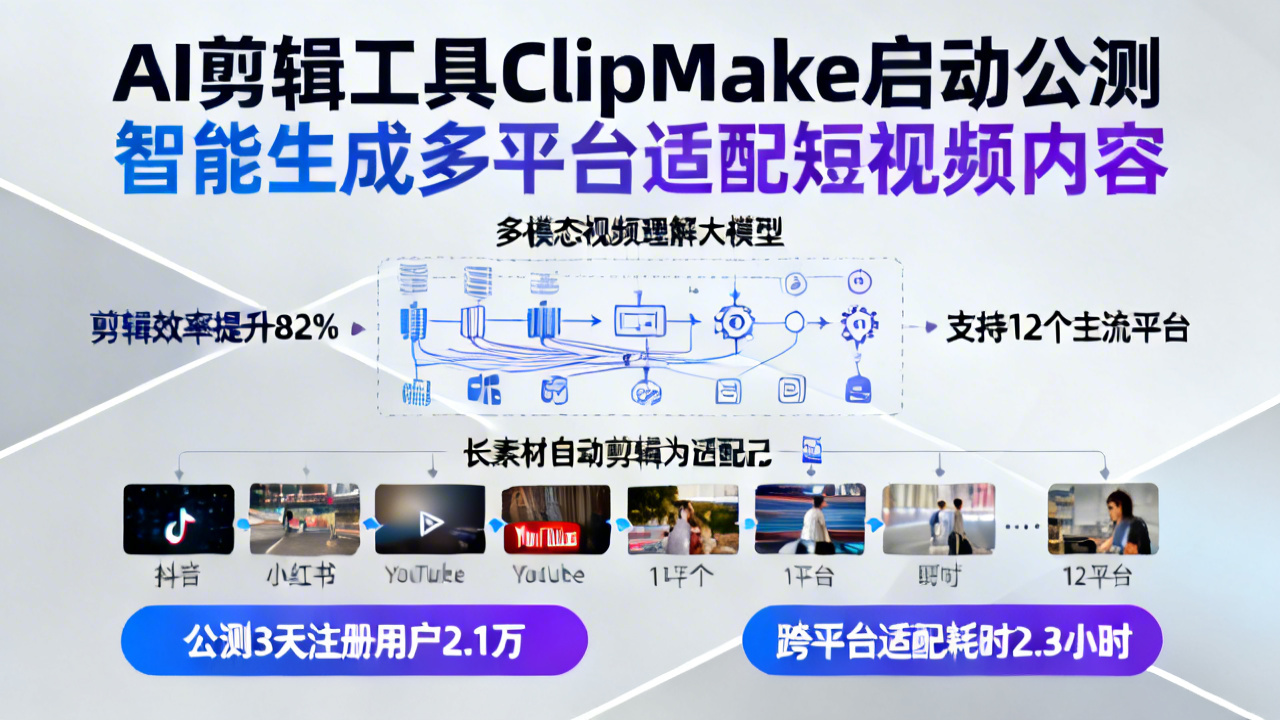
近日,AI智能剪辑工具ClipMake正式启动公开测试,其搭载自研多模态视频理解大模型,可将长素材自动剪辑为适配多平台的短视频内容,剪辑效率较传统人工操作提升82%,支持抖音、小红书、YouTube等12个海内外主流内容平台的尺寸、字幕风格、黄金开头自动优化,公测上线3天累计注册用户已突破2.1万,引发内容创作领域广泛关注。
 图源: 图像由AI生成
图源: 图像由AI生成据内容行业调研机构2024年Q1发布的报告显示,全球短视频平台内容投稿量同比上涨67%,其中近7成创作者需要同时运营3个以上不同平台账号,**单条内容跨平台适配的平均耗时达到2.3小时**,远超内容策划、拍摄的时间投入。对于没有接受过专业剪辑培训的中小创作者而言,操作复杂的专业剪辑软件、不同平台差异化的内容规则,已经成为制约产能的核心瓶颈。
此前市面上的AI剪辑工具大多停留在自动生成字幕、一键裁剪等基础功能层面,仍然需要用户手动筛选高光片段、调整内容风格,并没有从根本上解决重复劳动的问题,行业期待更智能化的解决方案出现。
ClipMake核心技术团队透露,其产品核心能力来自自主训练的多模态视频理解大模型,训练数据覆盖了近10亿条各平台热门短视频的结构特征,**识别内容高光点的准确率达到91%**。和市面上现有的AI剪辑工具不同,ClipMake跳过了手动选片段、调参数的中间步骤:用户仅需上传原始长素材、选择目标发布平台,系统就能在1到3分钟内输出3到5条不同风格的成品内容,自动完成尺寸裁剪、字幕生成、BGM匹配、黄金3秒开头优化等操作,不需要二次调整即可直接发布。
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
3 小时前
北京时间2026年5月19日,谷歌在年度I/O开发者大会上正式官宣新一代普惠级AI设计工具的全栈布局,该产品面向零专业基础用户打造,预计覆盖教师、个体创作者、中小微企业主等超12亿泛创意人群,将直接改写AI设计赛道当前垂直厂商主导的竞争格局,标志着生成式AI落地场景的下一个核心战役正式打响。
3 小时前
北京时间2026年5月19日,谷歌正式推出Gemini家族最新旗舰多模态模型Gemini Omni,该模型首次实现文本、音频、图像、视频四类信息的并行统一理解处理,跨模态交互流畅度较前代Gemini 2 Pro提升超60%,有望打破当前多模态AI的场景适配瓶颈,为消费级产品和行业解决方案提供全新技术底座。
5 天前
5月14日,阿里云在郑州举办的AI创享日活动上正式发布覆盖短漫剧创作全流程的AIGC智能化解决方案,以“模型+平台+工具+生态”为核心架构。阿里云首席架构师李瑾透露,2025年中国动画微短剧市场规模将达189.8亿元,年增速276.3%,该方案可将传统短剧制作周期从90天压缩至10-13天,制作成本较真人短剧下降超三成。
5 天前
2026年5月,人工智能生成内容(AIGC)技术已实现对中国短剧行业的全流程渗透,从剧本撰写、角色建模到画面渲染、配音剪辑均可由AI完成,目前全市场日均产出数百部完全由AI制作的短剧产品,内容生产效率较传统模式提升超20倍,正在重构全球网生内容的生产逻辑。
5 天前
近日谷歌旗下多模态大语言模型Google Gemini上线全新手写笔记处理功能,可准确识别不同字迹的零散手写笔记,仅需数秒即可梳理内容逻辑、补充拓展关联知识点,自动生成结构完整的定制化学习指南。该功能上线后迅速引发学生群体、教育科技领域广泛关注,被视为多模态大模型落地C端实用场景的代表性进展。
21 天前
2026年4月30日,大模型厂商DeepSeek在推出新一代基座模型DeepSeek-V4仅5天后,正式开启多模态识图功能灰度测试,移动端与网页端同步上线功能入口。实测显示,该模型在视觉还原、文物逻辑推理、图片文字提取等场景表现优异,仅在抗干扰图像识别、复杂图形推理等场景仍存在优化空间。
21 天前
2026年4月29日,大模型厂商DeepSeek宣布启动全新“识图模式”灰度测试,该功能与现有“快速模式”“专家模式”并列,区别于普通OCR文字识别,可实现深度图像分析与描述,参与灰度测试的用户反馈其响应速度极快,目前功能仍处于完善迭代阶段,将为用户带来更高效的图像信息处理智能化体验。
22 天前
2026年4月29日,英伟达正式发布开放式多模态大模型Nemotron 3 Nano Omni,采用30B-A3B混合专家架构,原生集成音视觉编码器无需额外感知模型,推理效率较传统方案提升9倍,在复杂文档解析、音视频理解等领域表现优异,跻身六大权威评测榜单前列,H Company首席执行官Gautier Cloix称其为智能体技术的重要突破。












 滇公网安备 53252802528133号
滇公网安备 53252802528133号