工具介绍:
Spice AI是面向数据密集型AI应用与智能体的开源运营数据湖仓,核心定位是帮助企业在现有数据资产基础上快速落地AI能力,无需额外改造数据架构。对比传统数据湖仓产品,它内置了查询加速、混合搜索、内嵌AI推理三大核心能力,可直接对接企业现有运营数据库、数据湖、数据仓库等异构数据源,目前已经在全球多家企业的生产环境落地,最高可帮助用户实现100倍查询提速、降低80%数据湖仓运营成本,同时提升核心工作负载的数据可靠性,适配从个人开发到企业级部署的全场景需求。
效果展示/案例参考:
企业用户对接多源异构业务数据后,原本需要数小时的跨库经营报表查询可缩短至毫秒级返回,数据运维成本降低60%;电商平台基于混合搜索能力搭建的商品搜索系统,语义匹配精准度提升42%,搜索响应速度提升3倍;AI智能体开发团队通过内嵌推理能力,可直接在数据查询层完成内容总结、实体分类等操作,AI应用开发周期缩短50%以上。
核心功能:
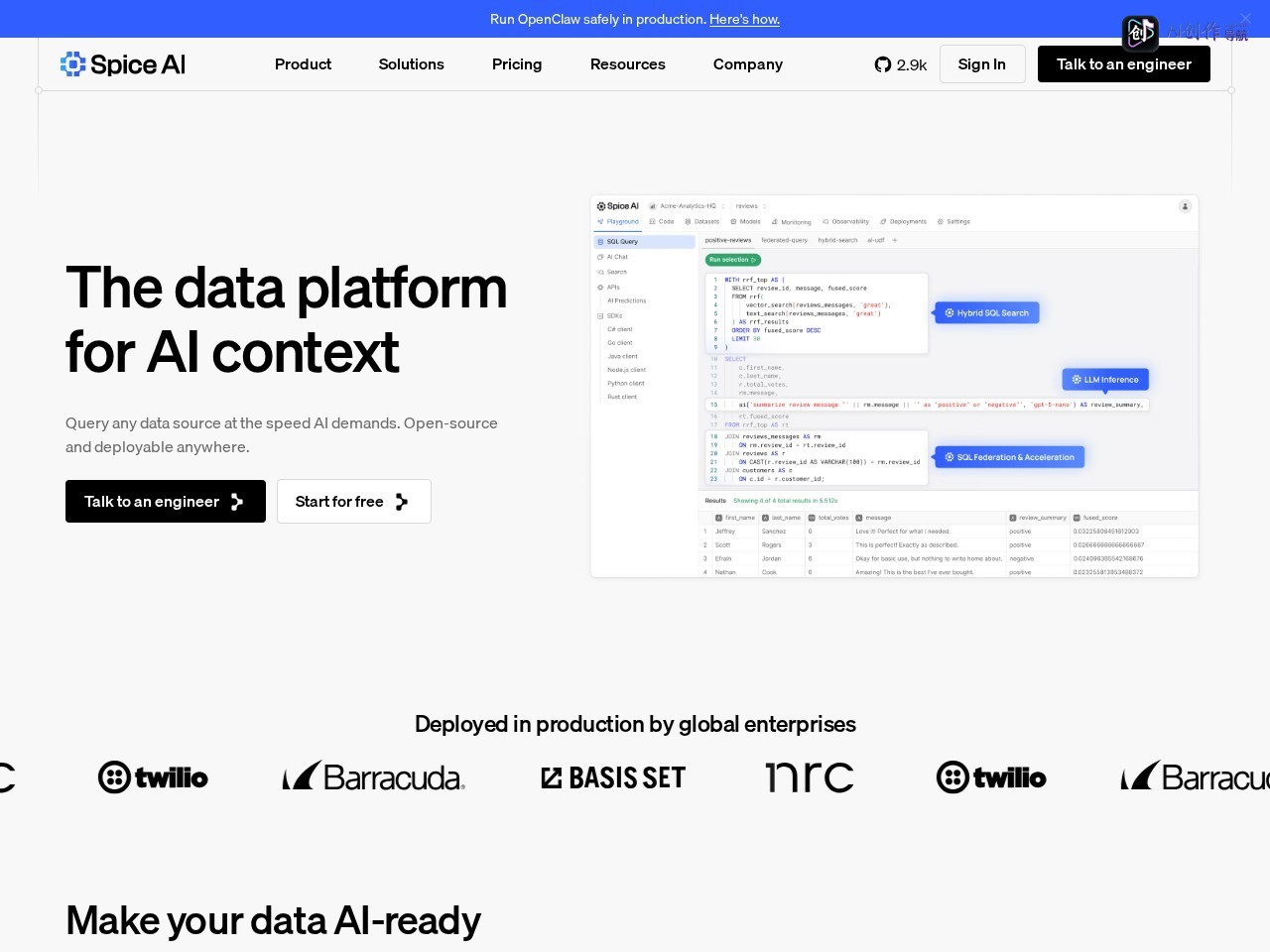
- 联邦SQL查询与加速:对接企业全量异构数据源,支持跨运营数据库、数据湖、数据仓库统一查询,支持工作集内存/磁盘物化,实现毫秒级数据访问。
- 多模态混合搜索:支持在标准SQL中融合关键词、向量、全文检索能力,可自定义排序规则优化搜索结果相关性,适配各类搜索驱动型应用需求。
- 内嵌AI推理调用:支持在查询层直接调用本地或托管大模型,通过SQL UDF或自然语言即可完成文本翻译、内容总结、实体分类等操作,无需跳转第三方工具。
- 零ETL数据接入:无需对现有数据资产做抽取、转换、加载处理,即可快速接入平台,大幅降低数据对接成本与周期。
- 企业级性能优化:核心工作负载数据可靠性大幅提升,最高可实现100倍查询提速,降低80%数据湖仓运营成本,适配生产级部署需求。
使用流程:
- 步骤1:访问Spice AI官网注册账号,根据自身需求选择免费版或企业付费版开通服务。
- 步骤2:按照平台指引对接现有数据源,无需ETL操作即可完成各类异构数据的接入配置。
- 步骤3:通过标准SQL即可完成跨源查询、混合搜索、AI推理调用等操作,也可根据需求自定义查询加速规则。
- 步骤4:将平台的查询能力对接至自身业务系统、AI应用或智能体,即可投入生产使用。
使用场景:
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
免责声明:本网站仅提供网址导航服务,对链接内容不负任何责任或担保。
 网站截图
网站截图



















 滇公网安备 53252802528133号
滇公网安备 53252802528133号