工具介绍:
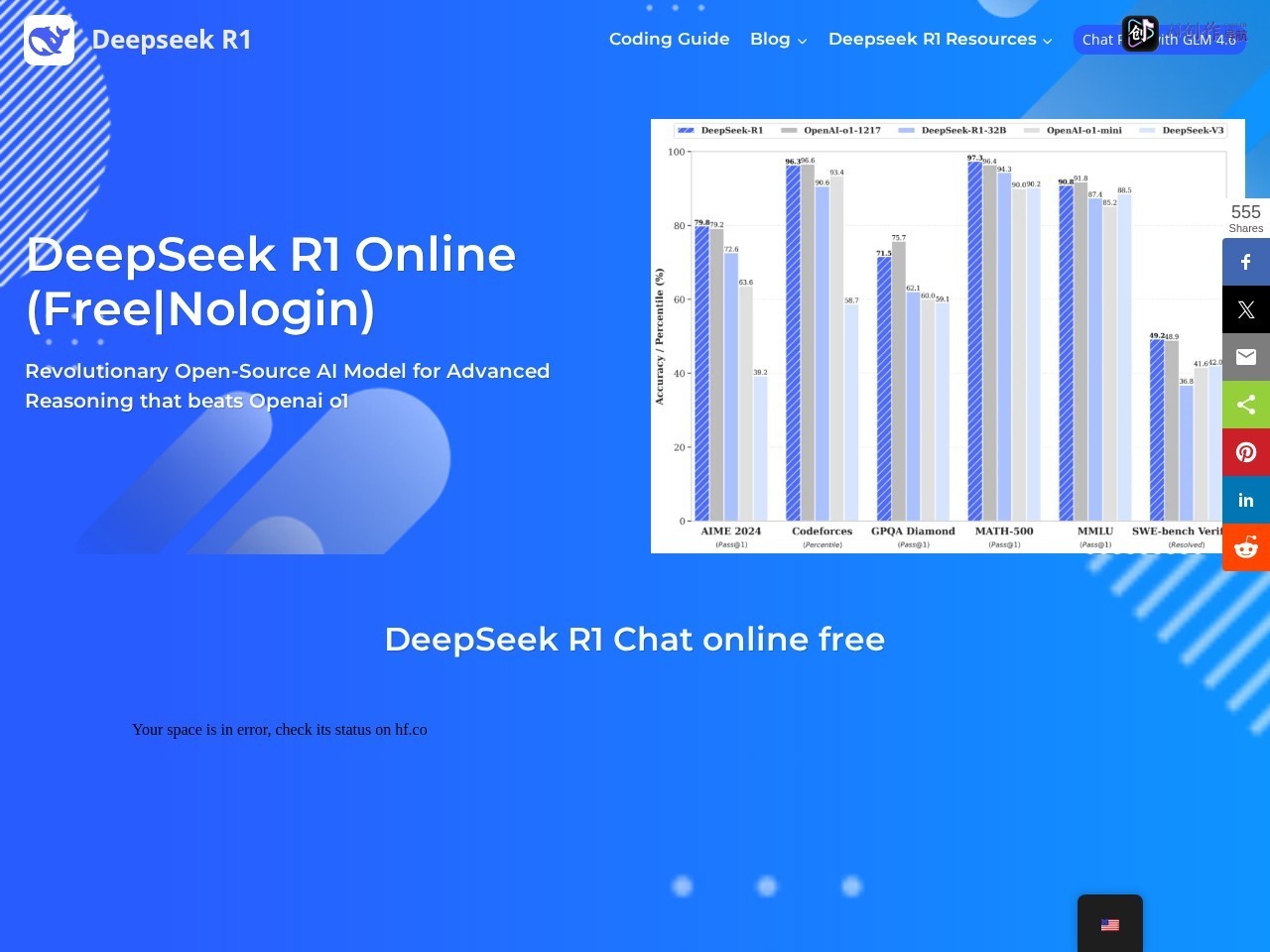
DeepSeek R1是一款面向推理场景的开源大模型,提供免费无需登录的在线体验服务,核心定位是为用户提供高性能的本地推理体验。该模型依托WebGPU加速技术,可直接在用户浏览器中完成本地推理,所有运算过程都不涉及数据上传服务器,加载完成后还支持离线使用。官方称这款开源模型的进阶推理能力超过OpenAI o1,兼顾了高性能推理与隐私安全,适合各类有推理需求的用户使用。
效果展示/案例参考:
在复杂逻辑推理场景下,DeepSeek R1可以输出连贯、准确的推理结果,比如数学应用题解答、逻辑谜题分析、项目方案逻辑梳理等,输出质量接近高端闭源大模型的水平。在隐私敏感场景,由于数据全程留在本地,不会出现数据泄露风险,使用安全感更强。模型加载完成后,响应流畅无服务器延迟,即使离线状态也能稳定输出结果,适配多场景使用需求。
核心功能:
- 本地浏览器推理:依托WebGPU加速技术,所有推理运算在本地浏览器完成,数据不上传服务器,保障用户隐私安全
- 免费免登使用:无需注册账号登录,即可免费体验模型能力,降低使用门槛
- 离线可用:模型首次加载完成后,可脱离网络正常使用,适配无网场景
- 开源推理架构:基于开源架构打造,推理性能优异,官方称推理表现超过OpenAI o1
- 轻量化适配优化:提供1.5B参数蒸馏版本,适配浏览器端运行,兼顾性能与运行效率
- 主流框架优化:基于Transformers.js和ONNX Runtime Web优化,运行稳定流畅
使用流程:
- 步骤1:打开DeepSeek R1在线网站,进入工具对话页面
- 步骤2:等待模型文件在本地浏览器完成加载,首次加载需要网络支持
- 步骤3:输入需要解决的推理问题或需求,等待模型输出结果
- 步骤4:加载完成后,可断开网络,继续离线使用模型
使用场景:
- 场景1:逻辑推理需求,满足数学解题、逻辑分析、方案推演等推理类需求,依托高性能推理能力获得准确结果
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
免责声明:本网站仅提供网址导航服务,对链接内容不负任何责任或担保。
 网站截图
网站截图






















 滇公网安备 53252802528133号
滇公网安备 53252802528133号