工具介绍
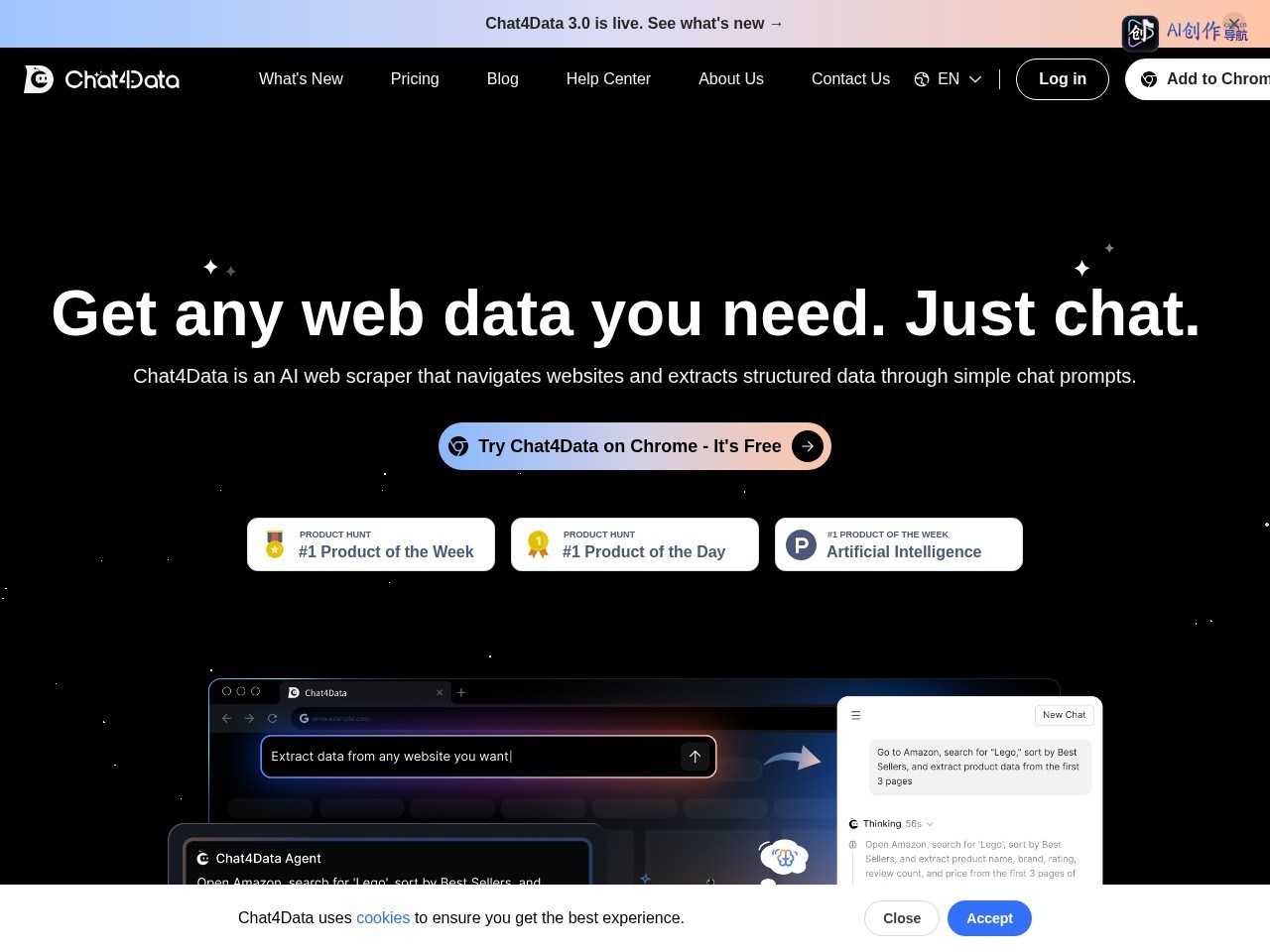
Chat4Data是一款搭载AI能力的网页爬虫Chrome插件,核心定位是降低网页数据提取门槛,用户无需掌握复杂的爬虫代码技术,仅通过自然语言对话就能完成全类型网页数据的采集工作。和传统爬虫工具相比,它能够自适应网页布局、代码的变动,即使网站更新页面结构也能精准定位目标数据,大幅提升数据抓取的稳定性,适配各类轻量级、临时化的网页数据采集需求。
效果展示/案例参考
用户只需输入“提取当前页面所有企业联系方式”的指令,Chat4Data就能快速输出结构化的手机号、邮箱列表,可直接导出为表格使用;如果需要采集商品列表页信息,输入“提取所有商品的名称、价格、销量链接”,工具会自动遍历页面元素,最终输出规整的结构化数据集,不会遗漏隐藏的有效数据,准确率远超普通的规则式爬虫。
核心功能
- 自然语言指令抓取:支持用自然语言描述数据需求,无需编写爬虫规则,大幅降低使用门槛。
- 网页结构自适应识别:同时识别网页视觉呈现和底层代码结构,页面布局、代码变动时仍能精准抓取数据。
- 全类型数据采集:支持一键抓取网页内的图片、链接、邮箱、手机号及各类隐藏元素,覆盖所有常见数据类型。
- 结构化数据输出:抓取到的原始数据会自动整理为结构化格式,可直接导出为表格等可编辑形式。
- 全网站适配:支持在任意网站使用,不受网站类型、页面结构限制,无需针对单站做特殊配置。
使用流程
- 步骤1:在Chrome浏览器应用商店搜索Chat4Data插件,完成安装并启用。
- 步骤2:打开需要抓取数据的目标网页,点击插件唤起Chat4Data对话界面。
- 步骤3:用自然语言输入你需要提取的数据要求,比如“提取本页所有招聘岗位的薪资、要求信息”。
- 步骤4:等待工具自动识别页面、完成数据抓取后,即可导出结构化的结果使用。
使用场景
- 场景1:市场调研人员采集竞品官网的产品信息、定价、用户评价等公开数据,无需手动复制粘贴。
- 场景2:内容运营人员批量采集行业资讯、公开报告的核心信息,快速整理素材库。
- 场景3:数据分析人员获取公开的行业数据、企业名录、联系方式等,为分析工作提供数据源。
- 场景4:销售人员批量抓取目标客户的公开联系方式、企业信息,快速搭建客户线索库。
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
免责声明:本网站仅提供网址导航服务,对链接内容不负任何责任或担保。
 网站截图
网站截图





















 滇公网安备 53252802528133号
滇公网安备 53252802528133号