



2026年3月25日,谷歌研究院正式发布全新极端压缩算法TurboQuant,针对大语言模型普遍存在的KV Cache内存瓶颈实现核心技术突破,实测可将AI内存占用锐降至原有水平的1/6,推理速度最高提升8倍。该技术有望重塑AI运行效率体系,对下游AI部署、存储芯片市场均将产生深远影响。
对于很多尝鲜本地大模型的用户来说,“爆显存”几乎是长文本生成、多轮对话场景下的标配痛点:哪怕是搭载24G显存的高端消费级显卡,跑70B参数的大模型最多也只能支持32k上下文窗口,再长就会因为内存不足直接崩溃。这一问题的核心根源,就是占大模型显存开销七成以上的KV Cache缓存。
KV Cache是大语言模型生成文本时的高速缓存机制,通过存储历史计算结果避免重复计算,是大模型提升生成速度的核心技术,但随着上下文窗口从4k一路扩展到128k、256k,KV Cache的内存占用也呈线性增长,成为制约大模型性能的首要瓶颈。
此前行业普遍采用高维向量量化技术压缩KV Cache,但这类技术需要为每个微小数据块计算、存储独立的量化常数,额外引入的内存开销抵消了近四成的压缩收益,始终无法实现根本性突破。云厂商的大模型推理成本中,显存开销占比已经超过60%,消费级设备跑大模型的门槛也始终居高不下。
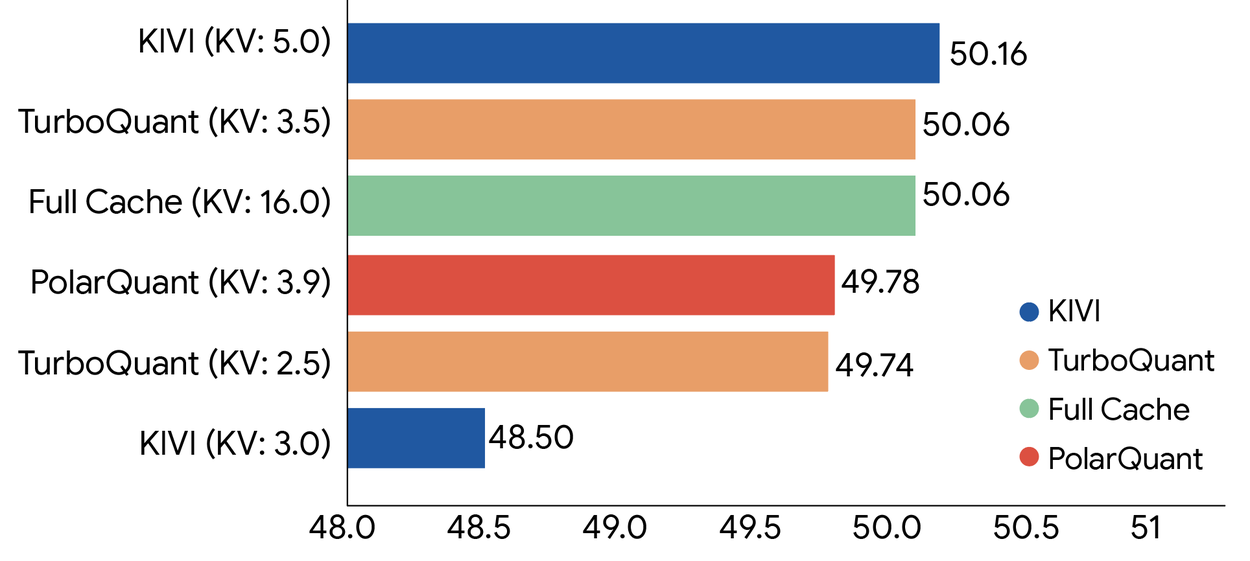
此次谷歌研究院推出的TurboQuant,直接放弃了传统分块量化的技术路线,采用全局动态量化校准机制,仅用极少量的全局参数就能实现对高维向量的无损压缩,完全消除了传统方案的额外内存开销,量化精度反而较行业主流方案提升12%。
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录















 滇公网安备 53252802528133号
滇公网安备 53252802528133号