工具介绍
Uberduck是主打“富有表现力AI vocals”的语音合成平台,核心解决“传统文本转语音仅支持说话、缺乏音乐性(唱歌/rap)、风格单一”的痛点,为机构、音乐人、营销人员及创作者提供“说话+唱歌+rap”一体化的语音合成服务。平台以“行业领先的准确性”为核心优势,能生成真实、有情绪的合成语音,不仅支持基础文本转语音,还能让AI“唱歌”“rap”,同时提供语音克隆、语音转语音功能,适配音频创作、内容配音、产品集成等多场景,是音乐人做demo、创作者做短视频音频的常用工具。
核心功能
- 文本转语音(含唱/rap):输入文本即可生成三种形式语音——日常说话、旋律化唱歌、节奏化rap,支持调整语气(如欢快、沉稳),适配短视频配音、音乐demo创作;
- API访问权限:开发者可通过API调用“文本转语音/唱/rap”“语音转换”功能,集成至自身产品(如音乐创作软件、短视频工具、虚拟形象项目),灵活适配业务需求;
- 语音克隆:上传参考音频生成自定义声音模型,让克隆声线支持说话、唱歌、rap,适合打造专属虚拟歌手声线、品牌定制语音;
- 语音转语音:实时将自身声音转换为目标声线(如将普通声线转为歌手风格),同时保留原说话/唱歌的节奏与情绪,适配直播变声、音频二次创作;
- 多语言支持:提供多种语言的语音合成选项(具体语言需在平台选择查看),适配跨境内容创作、多语言产品音频需求。
使用场景
- 音乐人创作辅助:独立音乐人输入歌词,生成AI唱歌/rap demo,快速测试旋律与歌词适配度,降低编曲前期试错成本;
- 短视频音频制作:创作者为剧情类、音乐类短视频生成AI配音(如rap式旁白)、背景音乐人声部分,提升内容趣味性;
登录后解锁全文,体验收藏、点赞、评论等完整功能
立即登录
免责声明:本网站仅提供网址导航服务,对链接内容不负任何责任或担保。
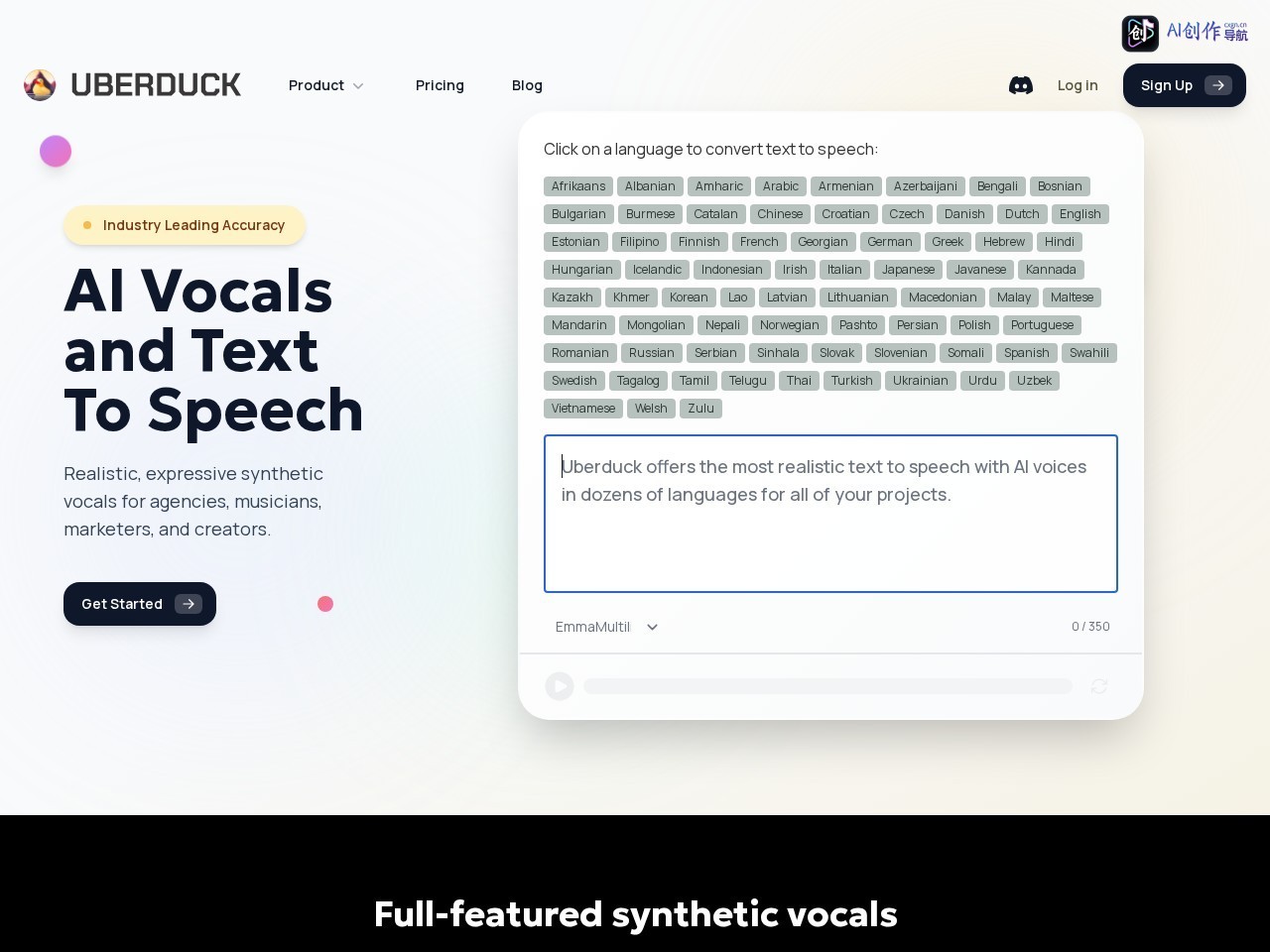 网站截图
网站截图



















 滇公网安备 53252802528133号
滇公网安备 53252802528133号